Persistence Query Model
A grasp of these concepts will help you understand this documentation better:
Only the Production version of your Persistence(s) will be executed. Therefore, please remember to DEPLOY TO PRODUCTION when you create (or modify) a Persistence for Holistics to execute it properly.
What is Persistence?
Model Persistence is the process of writing your data from your query model to your data warehouse to either make it available for querying, or to improve query performance.
Creating persistent table
In order to add the persistence to your query model, just simply add persistence: param to your query model
Model orders {
type: 'query'
label: "Orders"
data_source_name: 'demodata'
owner: '[email protected]'
query: @sql SELECT * FROM ecommerce.orders ;;
persistence: // ... your setting here
dimension id {
label: 'Id'
type: 'number'
}
// dimension ...
}
Full Persistence
Full Persistence is the process of rebuilding the whole persisted table each time it is triggered
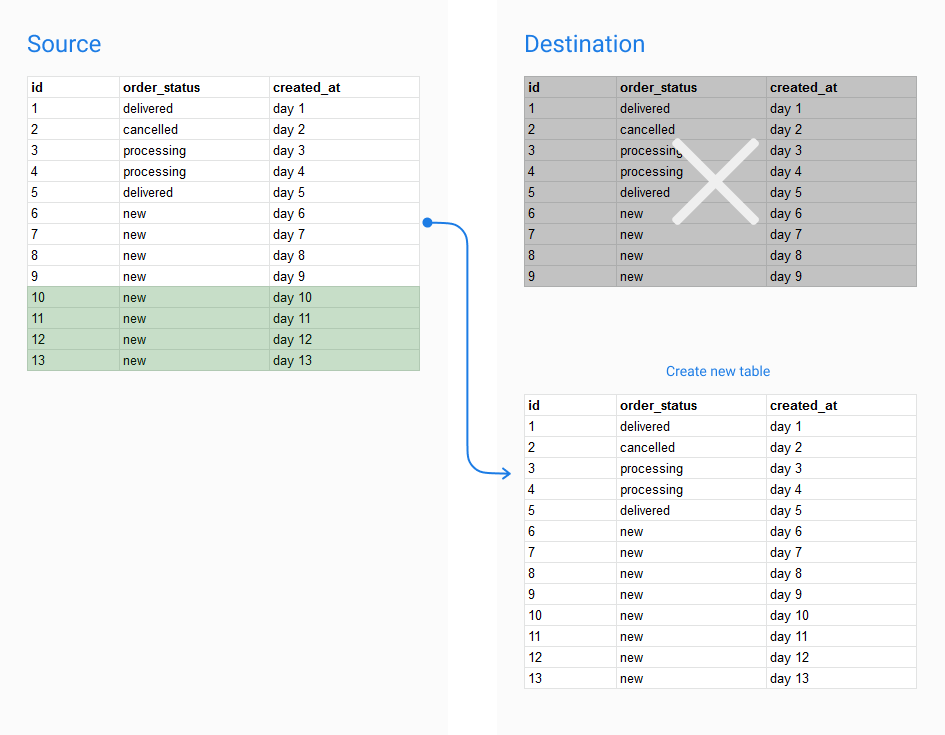
In order to execute Full Persistence, just simply add a FullPersistence config after persistence param
The FullPersistence config includes
schema: schema name that the persisted table will be written intoview_name(optional): allow Holistics to create a view table (in addition to thepersisted_table) with a consistent name in your database’s schema, so that you can reliably query it via SQL from outside of Holistics
Model orders {
type: 'query'
label: "Orders"
data_source_name: 'demodata'
owner: '[email protected]'
query: @sql SELECT * FROM ecommerce.orders ;;
// Fully regenerate the persisted table
// everytime the persistence was triggered
persistence: FullPersistence {
schema: 'scratch' // persisted table will be written into this schema
view_name: 'pqm_orders' //Optional
}
dimension id {
label: 'Id'
type: 'number'
}
// dimension ...
}
Incremental Persistence
Incremental Persistence is the persisted table that is built by appending only new records to the table instead of rebuilding the table in its entirety
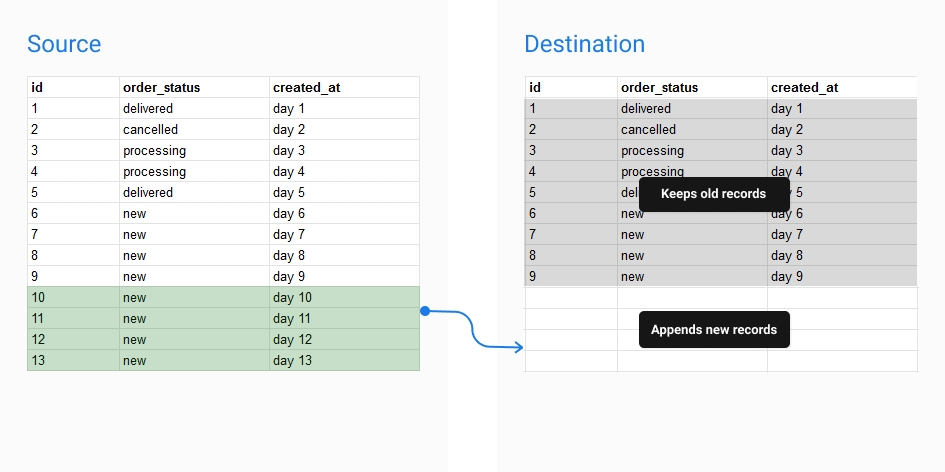
In order to execute Incremental Persistence, just simply add an IncrementalPersistence config after persistence param
IncrementalPersistence config includes:
schemaandview_name(same asFullPersistence)incremental_column: Holistics will use that column to determine the data range to be queried from the sourceprimary_key(optional): only use this option when your past records change. Holistics will refer to this column to delete changed records in the current persisted_table.
Model cancelled_orders {
type: 'query'
label: "Orders"
data_source_name: 'demodata'
owner: '[email protected]'
// Dependent models
models: [orders]
query: @sql
SELECT {{ #orders.* }} FROM {{ #orders }}
WHERE {{ #orders.status }} = 'cancelled'
;;
// Incrementally regenerate the persisted table
// everytime the persistence was triggered
persistence: IncrementalPersistence {
// Incremental only settings
incremental_column: 'updated_at'
primary_key: 'id'
// other options are the same as FullPersitence
}
dimension id {
label: 'Id'
type: 'number'
}
// dimension ...
}
How does incremental persistence work in 4.0
For now, users will need to specify the incremental column in the Persistence config in order for the Incremental Persistence to run as expected.
After specifying the incremental column, when the persistence is triggered, the query will be built like below
SELECT * FROM ( model query here ) WHERE [[ incremental_column > {{ max_value }} ]]
Note: this incremental mechanism might not be too optimal at the moment since the persistence condition cannot be customized. In the future, we might allow users to customize their own incremental persistence conditions.
Set Persistence trigger
This option is used to trigger your persistence based on a certain condition or schedule. In Holistics, Persistence Trigger is defined in a separate file.
Schedule trigger
Your persistence will be executed at the exact time that you have set. Schedule trigger will be defined in the schedules.aml file like below.
- AML 1.0
- AML 2.0
import './cancelled_orders.model.aml' { orders, cancelled_orders }
const schedules = [
// Schedule orders model to run every 10 minutes
Schedule { models: [orders], cron: '0,10,20,30,40,50 * * * *' }
// Schedule cancelled_orders model to run once an hour
Schedule { models: [cancelled_orders], cron: '0 * * * *' }
]
const schedules = [
// Schedule orders model to run every 10 minutes
Schedule { models: [orders], cron: '0,10,20,30,40,50 * * * *' }
// Schedule cancelled_orders model to run once an hour
Schedule { models: [cancelled_orders], cron: '0 * * * *' }
]
Holistics will scan the file schedule.aml and rely on the model name plus its corresponding schedule to build the related persisted table at the time set.
The content of the file includes
- import: all the query models you want to set schedule trigger
- schedule config:
- The config includes model's name and the cron job.
- You can set multiple schedules for one query model.
- Refer to cron example here for reference
Just a note:
- The persistence cannot be run at the exact time you set because of several reasons like
- Cascading persistence
- Run out of default slot for persistence queue
- The smallest frequency we support is every 5 mins since we only scan cron every 5 mins. If you schedule a persistence to run every 1 min it will simply run at the smallest frequency (5 mins)
SQL value trigger (not supported yet)
Persistence can be executed based on the value returned from a SQL statement that you defined. If the result of the SQL statement is different from the previous value, the persisted table is rebuilt. Otherwise, the existing persisted table is maintained in the database
Flow-based (Cascading) Persistence
There are cases where your persisted model refers to other persisted models which are its upstream dependent models.
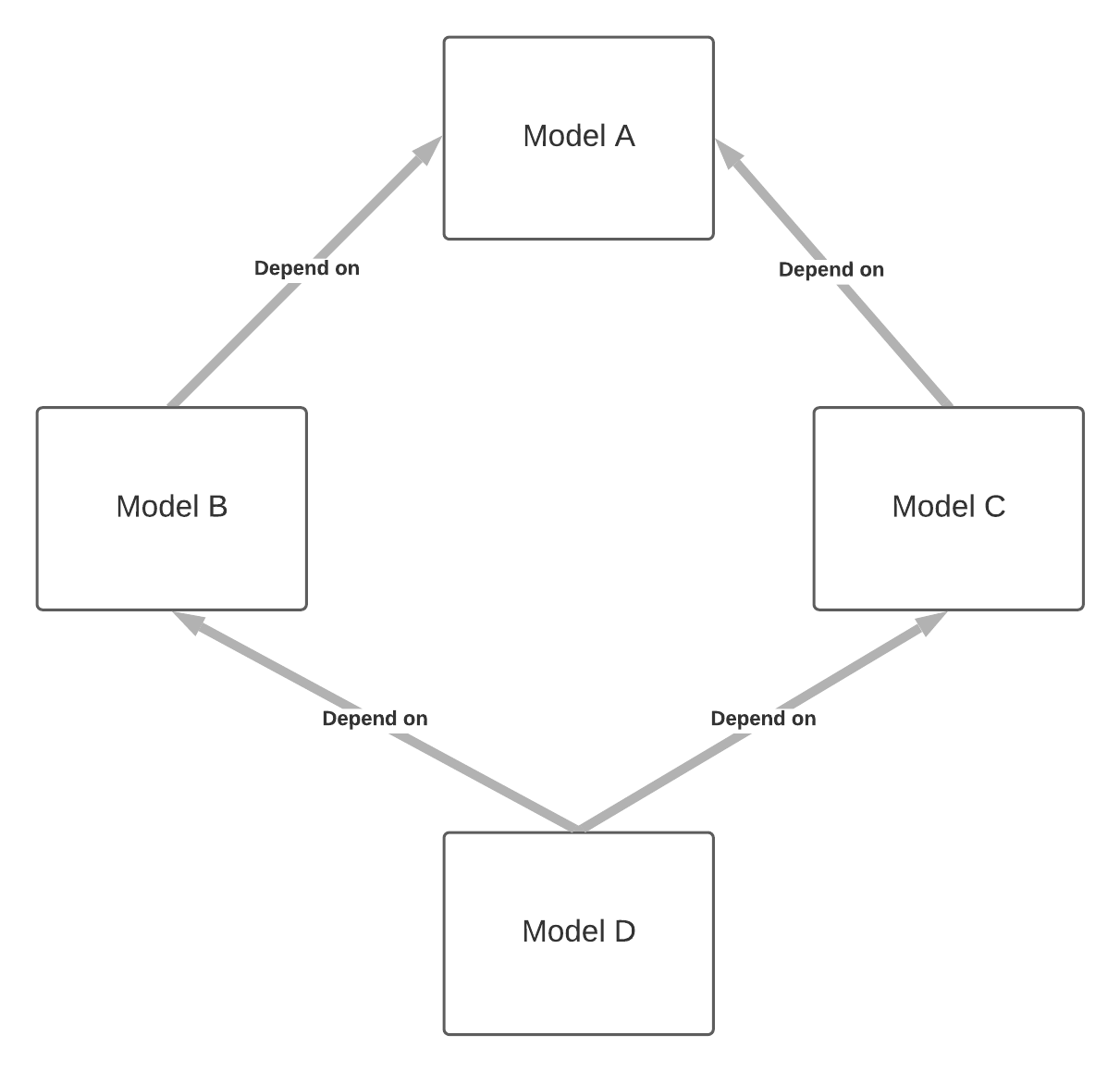
Let’s say you have the above set of SQL models that have references with each other. You now enable Persistence in all 4 models. In order to run Persistence in Model D, you can either choose to rebuild or reuse the Persistence in Model B, C, or A.
persistence: FullPersistence {
// persisted table will be written into this schema
schema: 'scratch'
view_name: 'pqm_orders' // Optional
// What to do when a downstream persistence cascade to the current one
// Available options:
// 'rebuild' (default)
// 'reuse' Reuse the last persisted table if available
on_cascade: 'reuse' | 'rebuild'
}
Rebuild cascade
Note: rebuild cascade will be run by default if on_cascade is not set
By setting the on_cascade key to ‘rebuild’, the persisted table of the current model will be rebuilt when its downstream dependent models are triggered or rebuilt.
Reuse cascade
By setting the on_cascade key to ‘reuse’, the persisted table of the current model will be reused in the downstream persistence models. Do note that if the Persistence is triggered by a schedule (in schedule.aml file), it will be rebuilt and disregarded on_cascade setting.
For the most part, you should only use 'reuse' in these two scenarios:
- The model’s data is static
- You want to control the exact timing of the persistence process. E.g: enable reuse and add a schedule to refresh at 6AM everyday ⇒ it will only be rebuilt once everyday at that time, regardless of other cascading.
Order of persistence execution
Let’s say, for example, we set on_cascade of Model D to ‘rebuid’, B to ‘reuse’, C to ‘rebuild’, A to ‘rebuild’
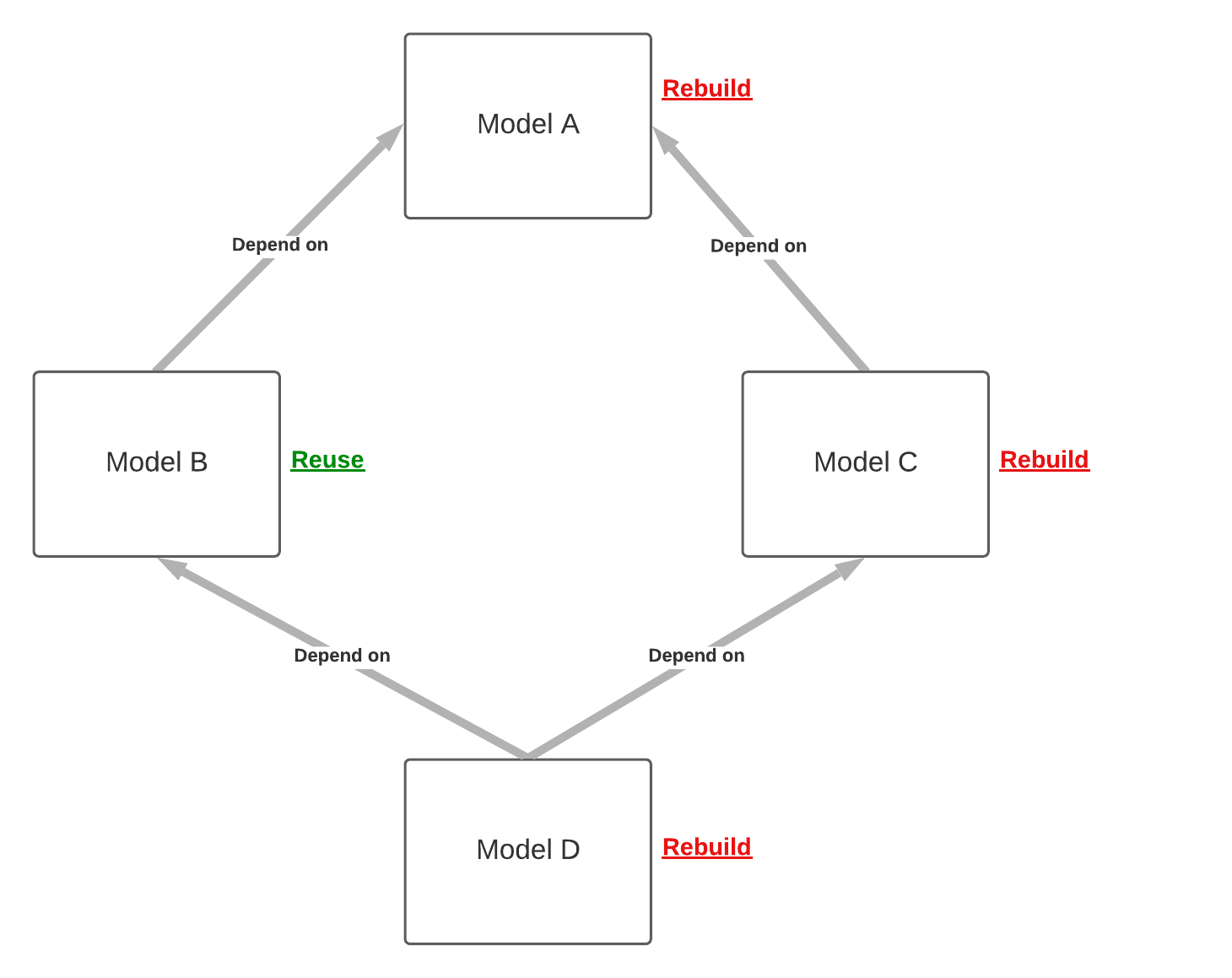
B uses the on_cascade: 'reuse' strategy. A, C, and D use on_cascade: 'rebuild'
Thus:
Schedule { models: [D] }A will still be rebuilt even if B uses the'reuse'strategy since C uses the'rebuild'strategy.Schedule { models: [B] }will rebuild B, since the direct trigger won't respect theon_cascade: 'reuse'strategy (because it's not a cascade trigger).[Schedule { models: [A] }, Schedule { models: [B] }]here since A and B belong to different pipelines, A will always be rebuilt regardless of B.
When will the persisted table be invalidated?
There are two cases when the Persisted table is invalidated and removed:
- These persisted tables will be retained for 24 hours (from after the persistence is deleted or the related schedule is removed on production).
- When the current model or upstream dependencies changed. This includes a change to query, incremental column, primary_key, model name, etc.