Import Model
Definition
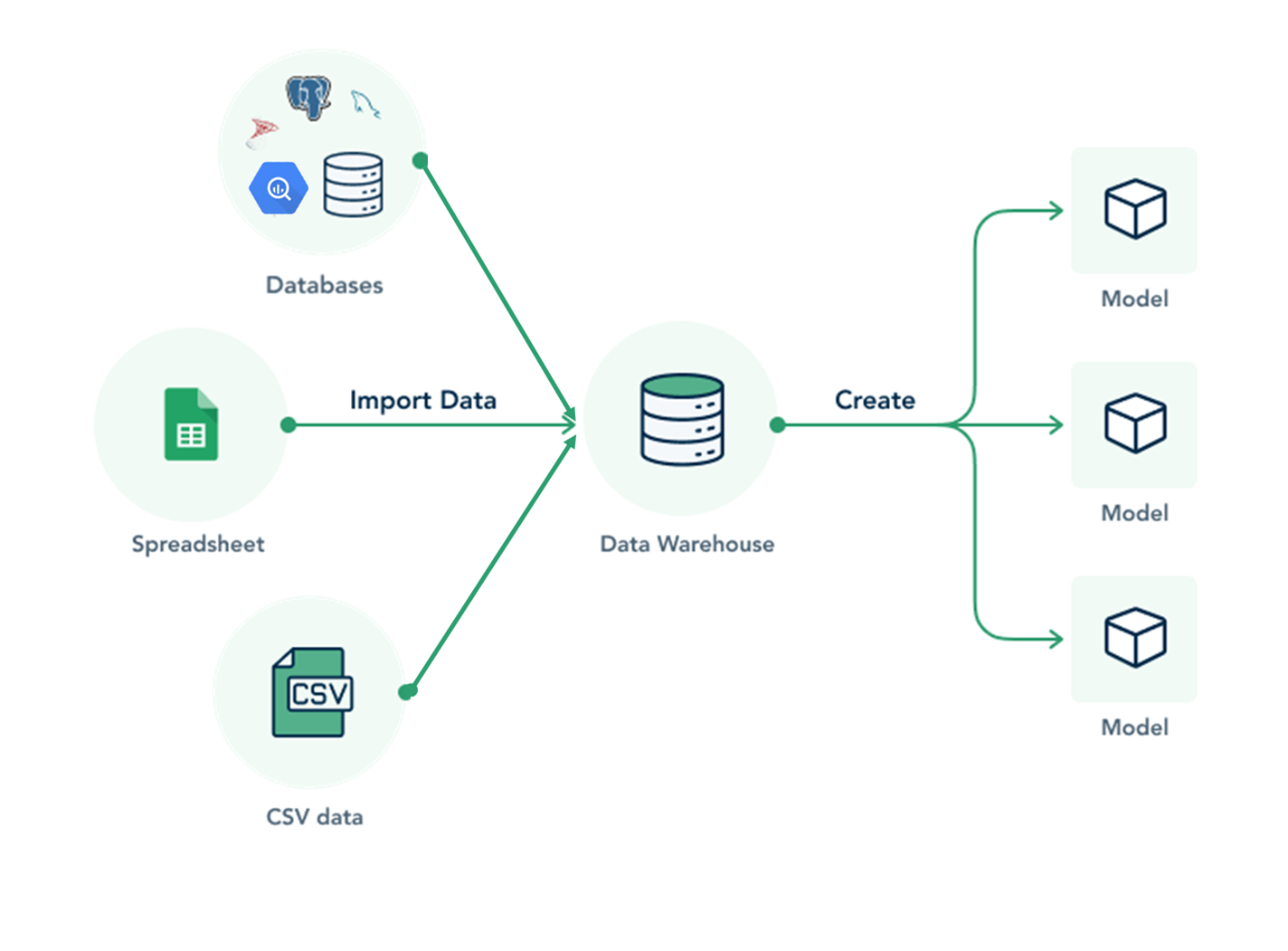
In Holistics, Import Model is a data model created when you want to import data from other data source into SQL database (EL in ELT).
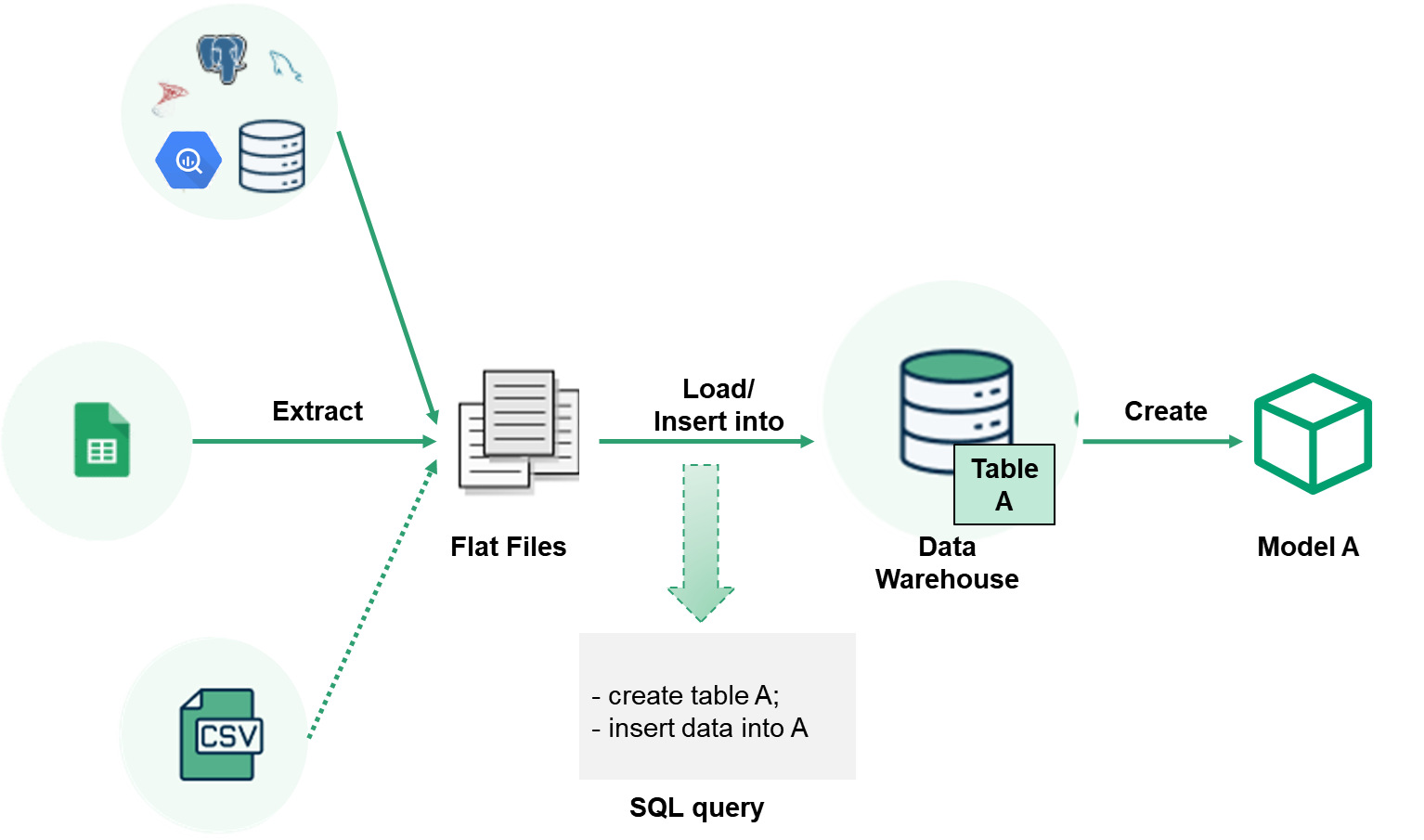
Under the hood, an Import Model is a data model coupled with an Extract-Load mechanism to help you load data from other data sources (CSV, Google Sheets, etc).
Note: Holistics's Import Model is designed for you to quickly get started with your reporting needs, and do not intend to replace full-fledged data integration solutions.
How It Works
When creating an Import Model, this is what happens behind the scene:
- Holistics connects to your third-party source via its API and extracts the requested data.
- The downloaded data is then inserted into a destination table in your data warehouse.
- When loading data into data warehouse, you can create a new table or append to or overwrite an existing table.
- That table is then exposed as a data model in the Holistics modeling layer.
Supported Data Sources
Import Model currently supports the following data sources:
- Application: Google Sheets, CSV files
- SQL database: SQL Server, PostgreSQL, MySQL, Google BigQuery, Amazon Redshift.
Creating Import Model
First, make sure your SQL data warehouse has write permission, so that Holistics can write the data into the DW.
Then, follow these steps:
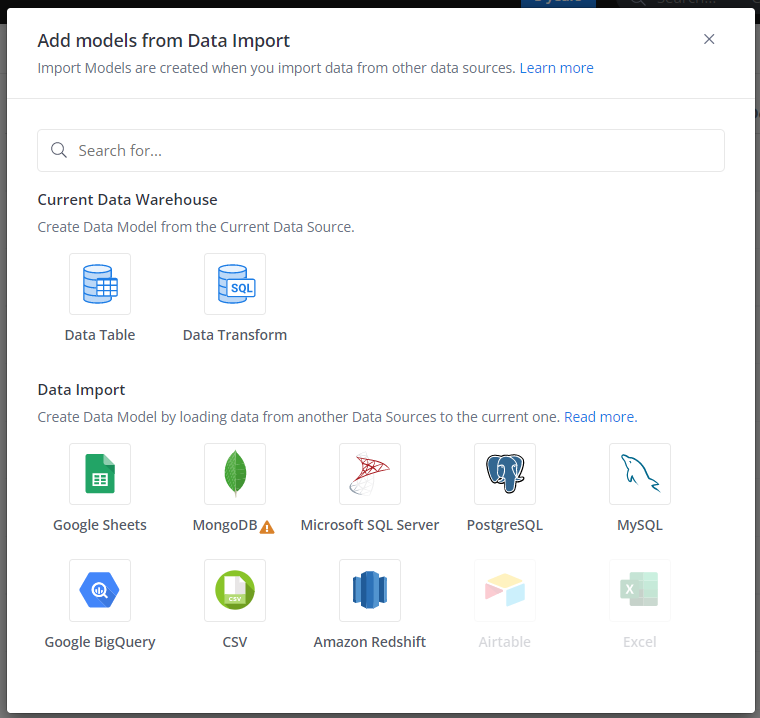
- Go to Data Modeling page, click Create -> Add Import Model, or click the (+) next to the folder that you want to put your Import Model in.
- Select a data source type. If there is no available data source of that type, you will be prompted to connect a relevant source (visit Data Sources for more details)
- Select the data you want to import.
- Change Destination Settings and Sync Configuration to your liking.
- Click Create to finish the process.
We do not support loading multiple flat files into one data model, each file will create a new import model
Advanced Settings
Advance Settings section gives you more granular control of your data import:
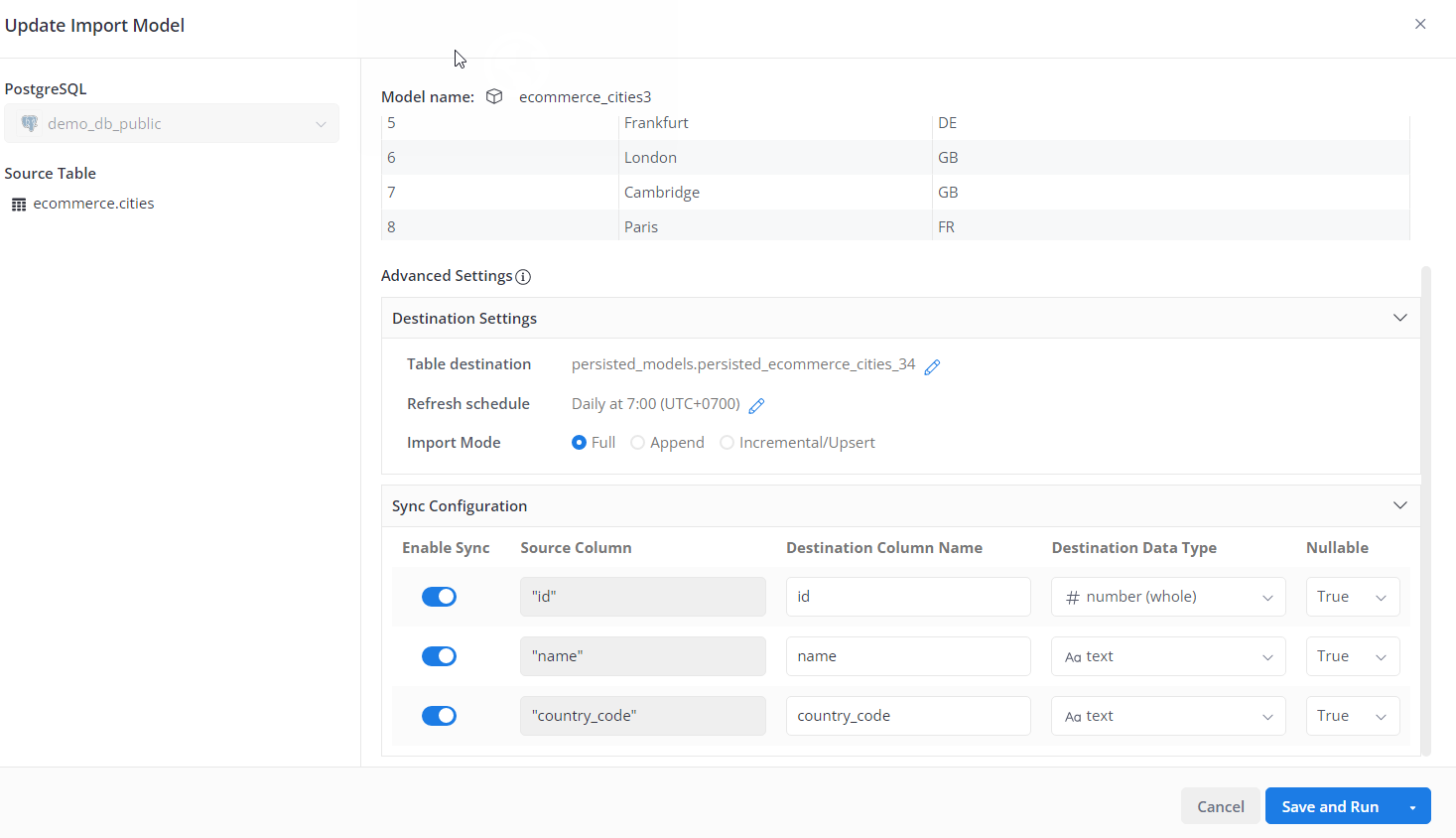
Destination Settings
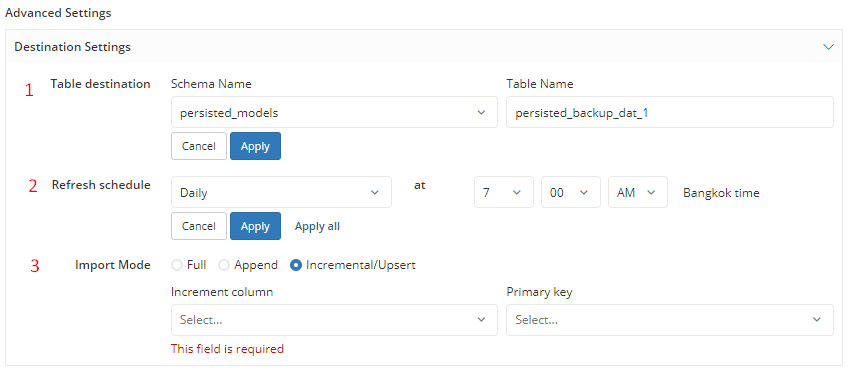
Table Destination
Here you can specify the schema and the table name to write your data to.
- The Schema Name will default to the Default Schema that you selected when you first connected your data source.
- The Table Name by default will be prefixed with
persisted_. If a table with the same name already existed in the schema, the new name will be suffixed with a random number to differentiate it. However, you can choose to overwrite the existed table.
For example, your Source Table name is Users and the Default Schema in your Destination is public, then your corresponding table in the destination will be public.persisted_users.
Refresh Schedule
By setting the Refresh Schedule, the persisted table can be automatically updated with new data. The default option is Daily at 7:00.
Import Modes
Currently Holistics support Full, Append and Incremental/Upsert modes. For more details on how these modes work, please refer to our docs on Storage Settings.
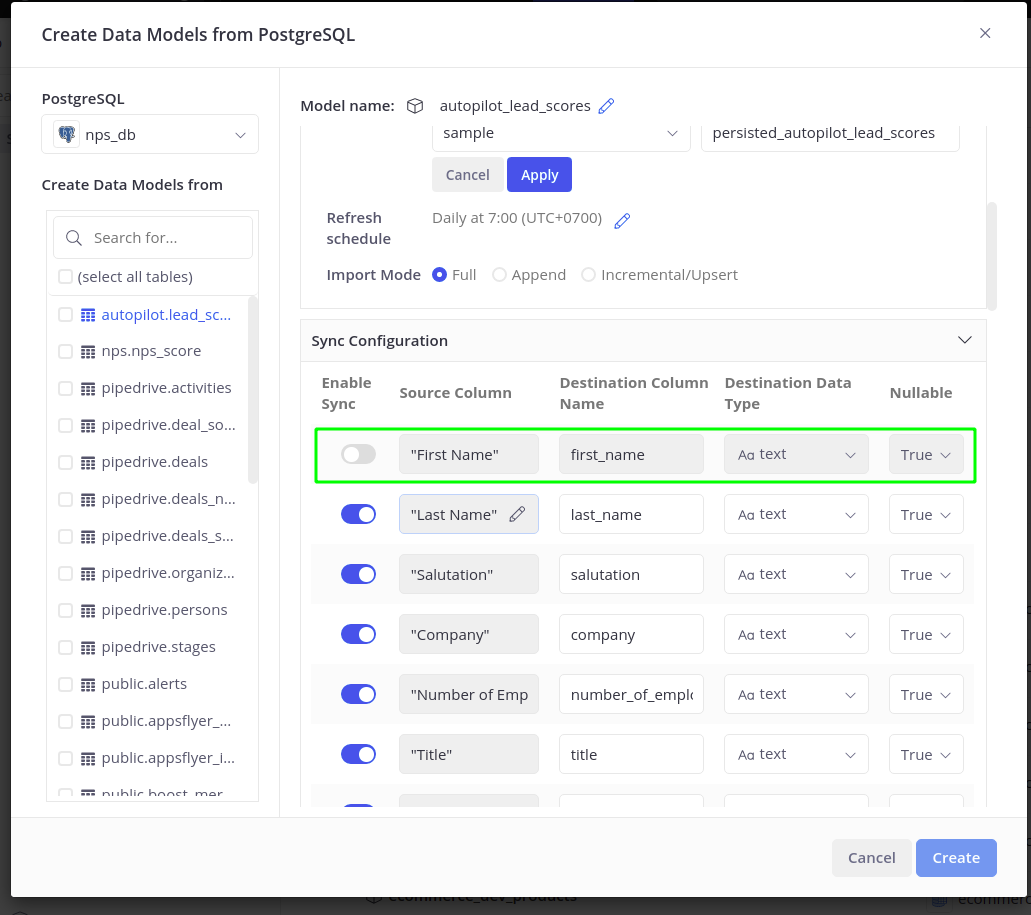
Sync Configuration
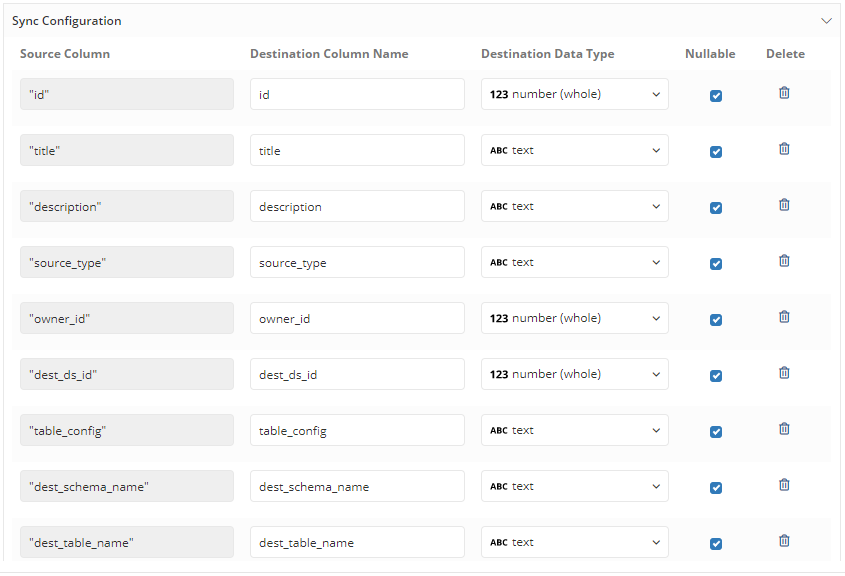
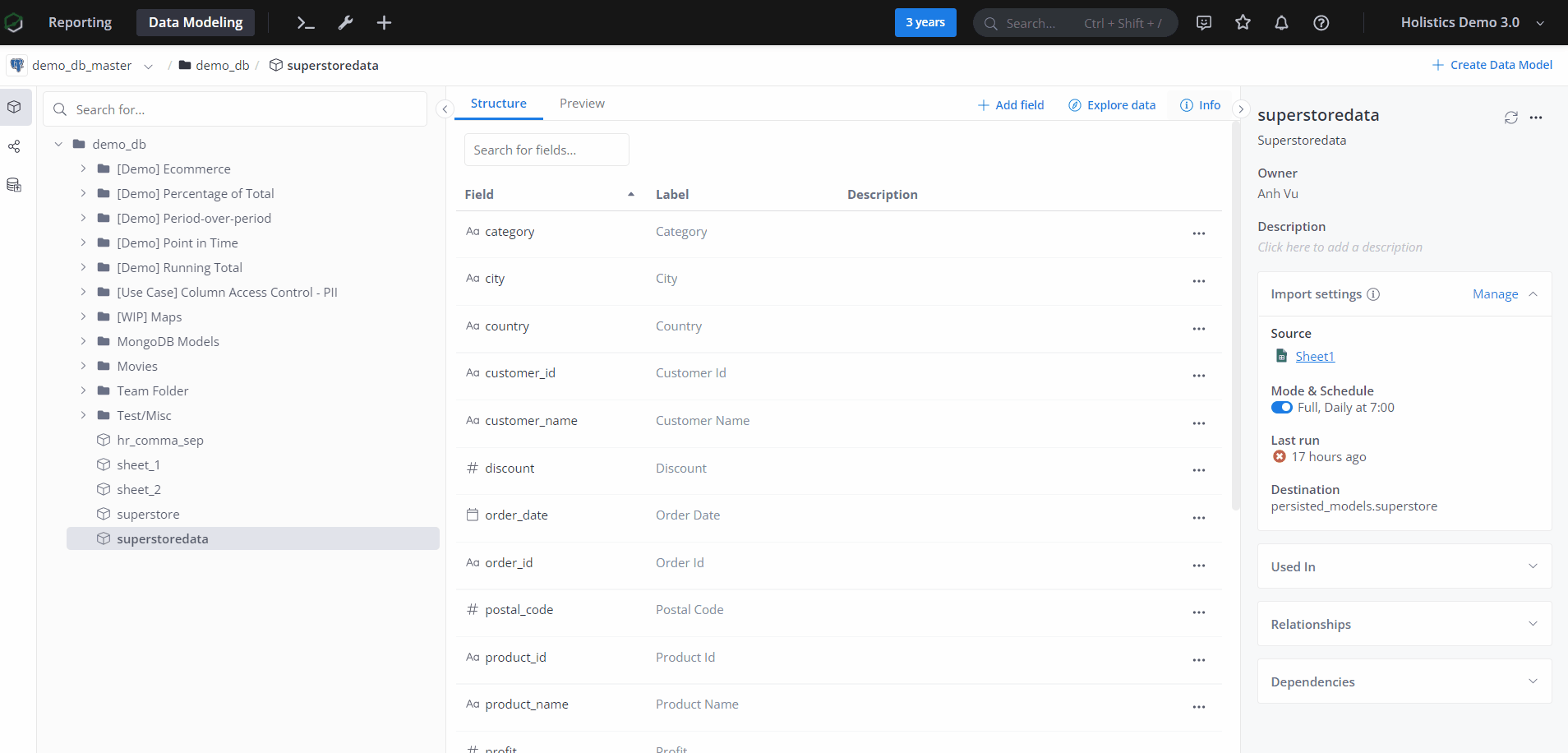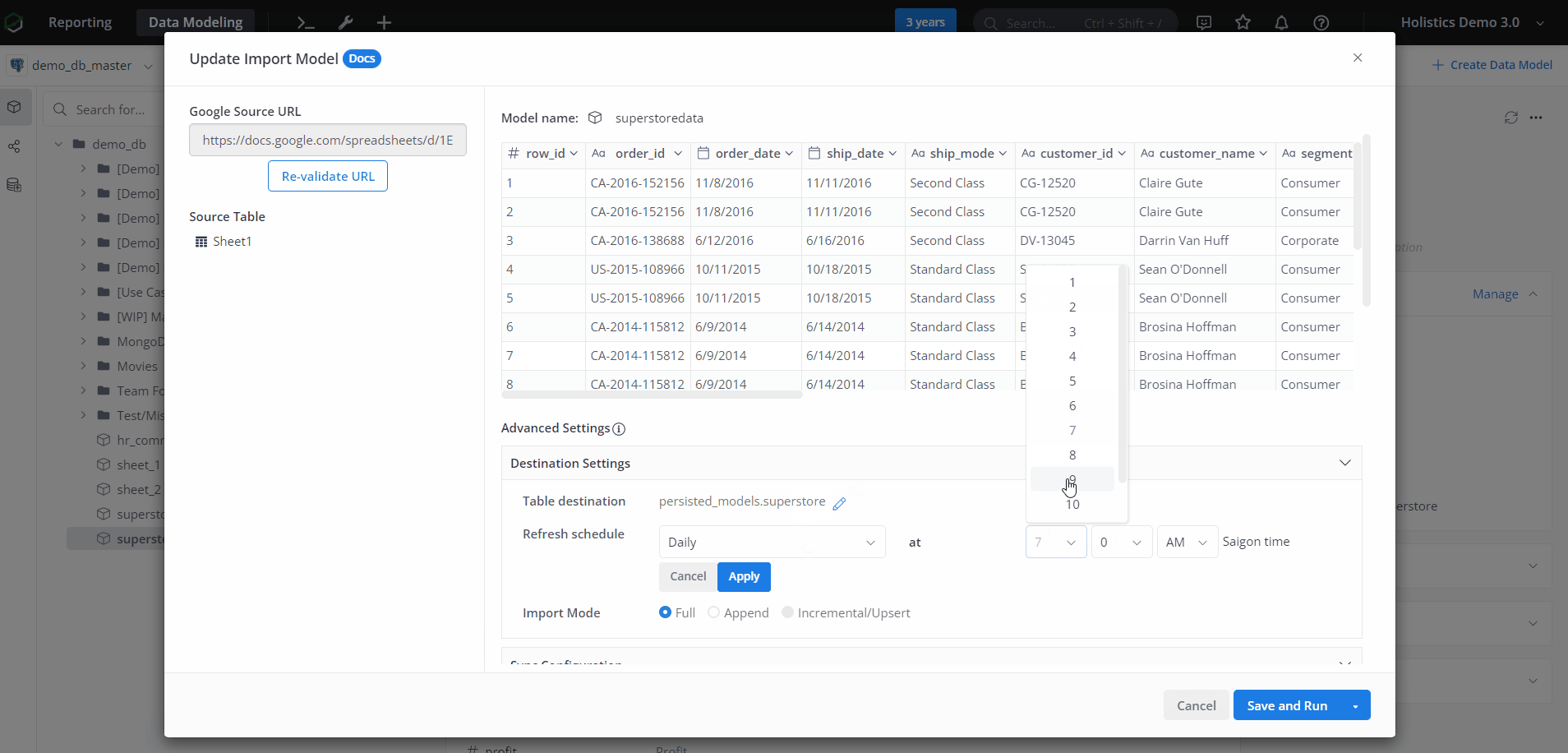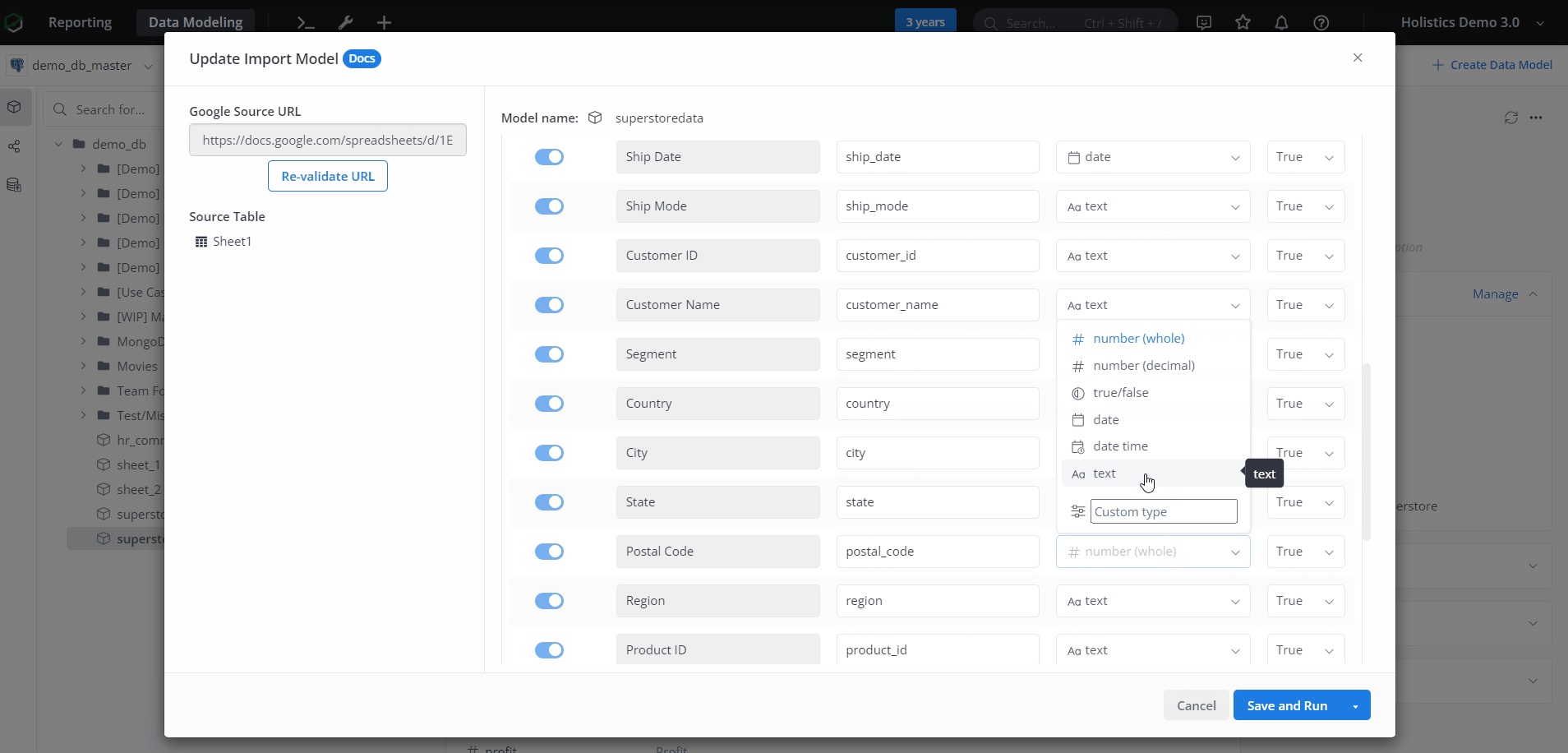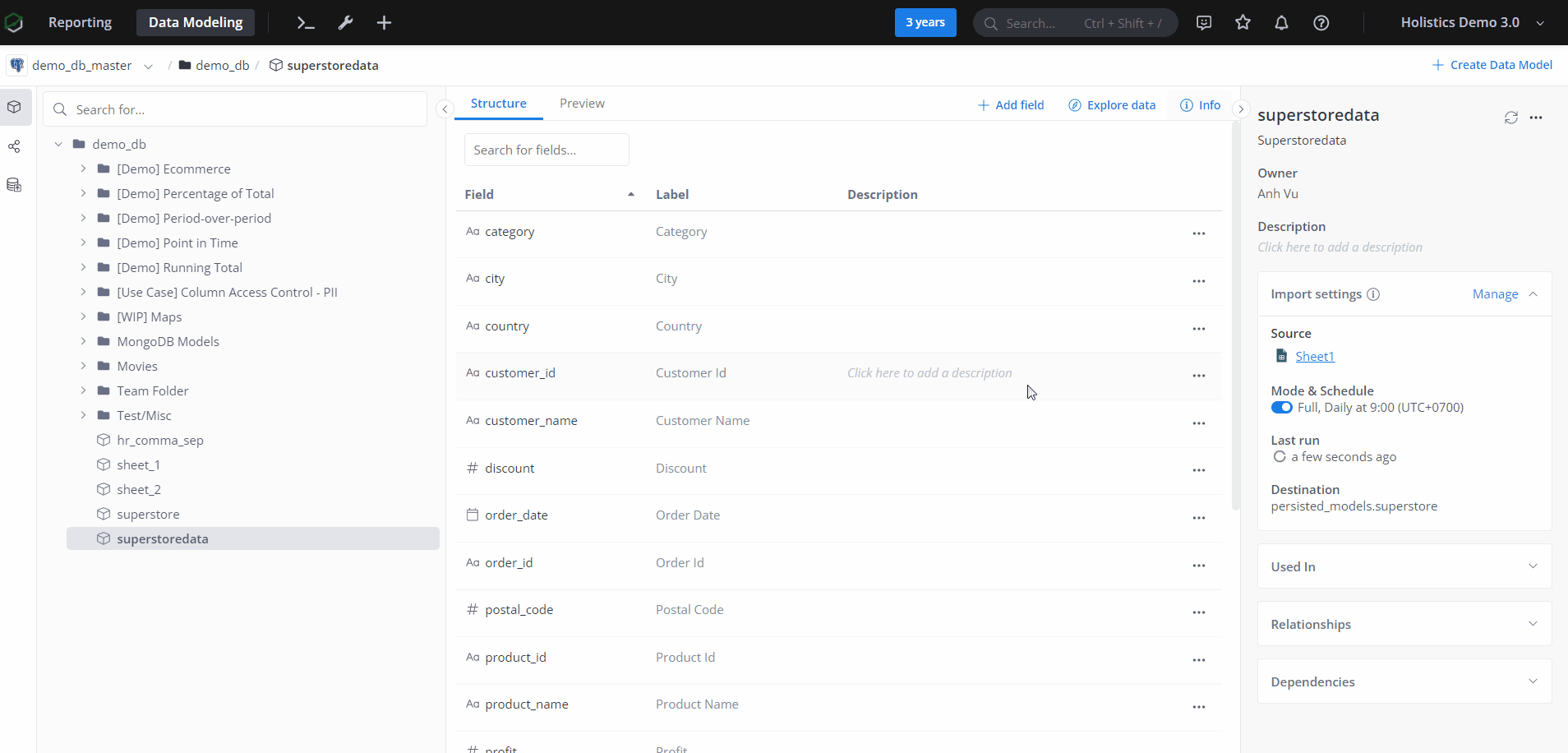
Destination Column Name
Source Column names could be arbitrary if the data source is not a standardized one (for example CSV files, or Google Sheets). By default, Holistics will normalize the source column names (use all lowercase alpha-numeric characters and underscores). However, users should still pay attention to the different naming conventions supported by databases and make changes accordingly.
Destination Data Type
To best assist users when importing data, Holistics will:
- Map your data to one of the Generic Data Types first (Whole Number, Decimal, TrueFalse, Date, DataTime, Text)
- Then select the suitable data type in your destination database.
For example, you want to import data from SQL Server and your destination Data Warehouse is Google BigQuery. The source table in SQL Server has columns in BIGINT, INT, SMALLINT, TINYINT. What will happen in Holistics:
- The integer columns in SQL Server are mapped to our Whole Number data type
- Next, the Whole Number data type is mapped to
INT64type in BigQuery
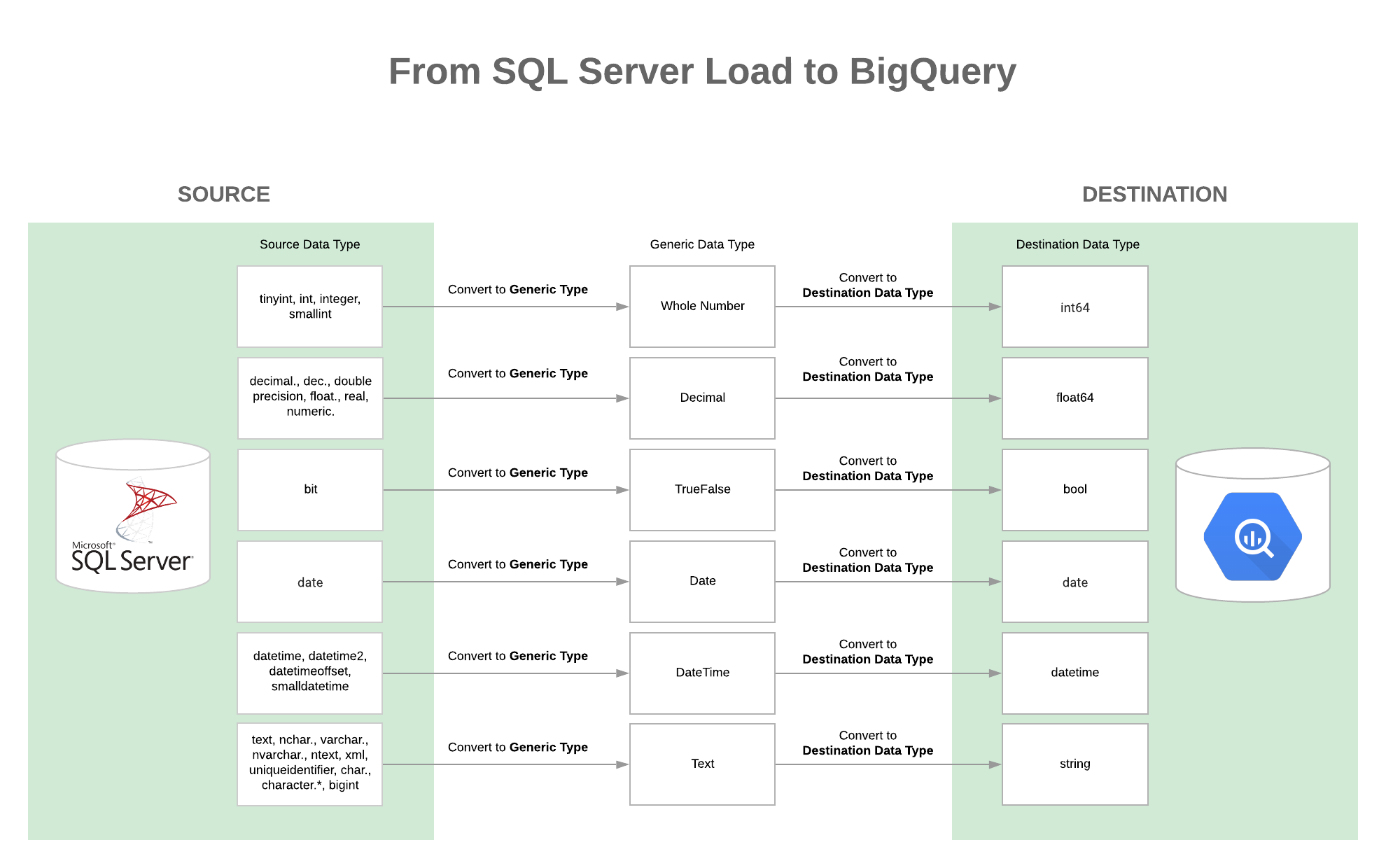
Please refer to the Data Type Mappings section for more details.
In most cases, Holistics can interpret the data being loaded in and map your fields to data types supported by the destination database. However, in more complicated cases you can manually map data types by using the Custom type selection:
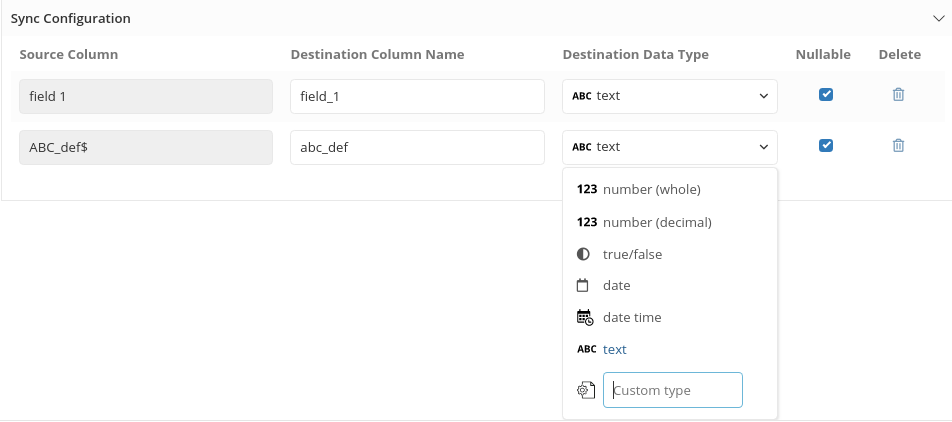
Other config
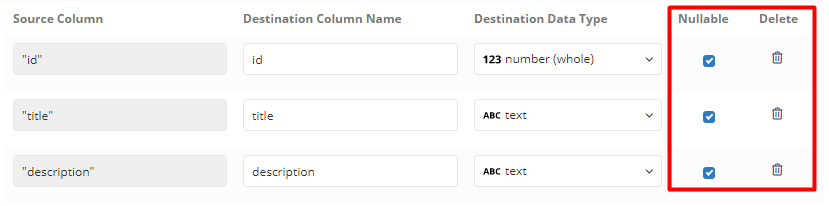
Nullable If this is checked, the column is allowed to have NULL. If unchecked, the loading operation will fail if there is a row in the column with no value. This particularly is useful when you want to validate your data logic.
By default, all the columns in Sync Configuration will be Nullable
Delete Column If you want to exclude any columns from being loaded to the Destination, you can remove them here. Currently, this option is not available for no-SQL Data Sources (Spreadsheet, CSV,...)
Data Type Mapping
Source Data Types and corresponding Generic Data Types
| Source | Whole Number | Decimal | TrueFalse | Date | DateTime | Text |
|---|---|---|---|---|---|---|
Postgres | smallint., int., serial., smallserial. | double., real., decimal., numeric. | boolean | date | timestamp.* | varchar., char., enum., text., binary., bigint., bigserial.* |
BigQuery | integer | numeric., float. | bool | date | datetime, timestamp | string, bytes, int64 |
MySQL | tinyint., smallint., mediumint., int. | decimal., float., double.* | n/a | date | timestamp, datetime | varchar., char., text., longtext., enum., binary., blob., varbinary., bigint.* |
SQLServer | tinyint, int, integer, smallint | decimal., dec., double precision, float., real, numeric. | bit | date | datetime, datetime2, datetimeoffset, smalldatetime | text, nchar., varchar., nvarchar., ntext, xml, uniqueidentifier, char., character.*, bigint |
Google, CSV | n/a | n/a | n/a | n/a | n/a | always text |
Oracledb | number.* | float.* | n/a | date | timestamp.* | varchar., nvarchar., varchar2., char., nchar., nvarchar2., long., blob., raw., long raw. |
Generic Data Types and corresponding data types in Destination
| Destination | Whole Number | Decimal | TrueFalse | Date | DateTime | Text |
|---|---|---|---|---|---|---|
Postgres | integer | double precision | boolean | date | timestamp without timezone | text |
BigQuery | int64 | float64 | bool | date | timestamp | string |
MySQL | integer | double precision | tinyint(1) | date | datetime | text |
Oracledb | number | number | number(1, 0) | date | date | nvarchar2(1000) |
SQLServer | int | real | bit | date | datetime2 | ntext |
- The suggested data type is based on a sample of your data, so in some cases, it could fail if there are unexpected values in your data (for example, in a Google Sheet the first few rows can have numeric values but in a later row a string value can be mixed in.)
- If the data type cannot be interpreted, it will be mapped to Text type.
Editing Import Model
After creating the import model, you can still adjust its settings (destination and sync configuration).
You tend to edit the import model whenever:
- You have set a field's Data Type incorrectly and the import job fails
- You want to change your Destination Settings (Refresh Schedule, Import Mode...)
- ...
In those cases, click on Edit in Import Settings and the Import Model Editor view will appear.
Refresh Source Structure of Import Model
When your sources' structure has some changes (columns are added, deleted or renamed...):
In the case of Google Spreadsheet imports, we do not automatically update the Source structure for you - you will need to click on the Re-validate button to get the updated structure. Note that this will also revert all of the column names and data types to default.
In the cases of Database Table imports (from PostgreSQL, MySQL, SQL Server, BigQuery), we will automatically update the Source structure for you. If there are new columns in your Source, they will appear in the Sync Configuration's field list but are not enabled. To include them in the sync, you will need to toggle them on.